
前言
小帽子alfred可以说是macOS上最佳的效率软件了,而其中最强大的功能就属alfred 2.0推出的Workflow特性了。就像我们工程师遇到重复性工作总是想写脚本或者程序来解放自己一样,workflow功能允许你将日常重复性的工作通过使用脚本语言(bash、zsh、php、ruby、python、perl、as、js)封装起来,通过alfred作为统一入口进行使用。
因为alfred的受众之广,所以写workflow被设计的门槛非常低,低到了官方都没有写文字教程,只在alfred内嵌了几个demo给用户自己学习。本文将使用一个示例来详细说明workflow的开发流程。
用户界面
安装好alfred以后,使用默认快捷键 option + space 打开alfred入口:

Command + , 打开设置页面:
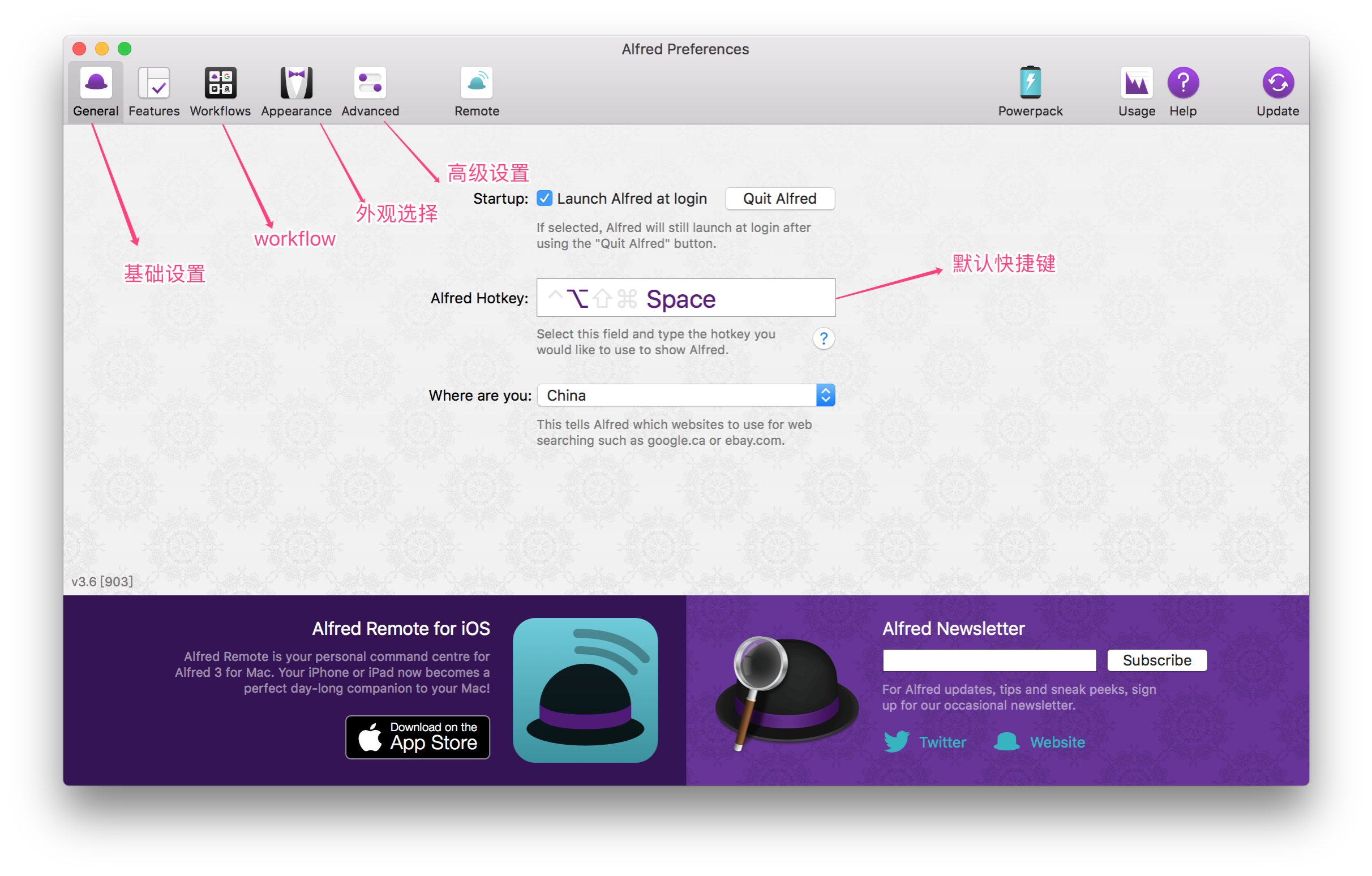
打开workflow选项卡:
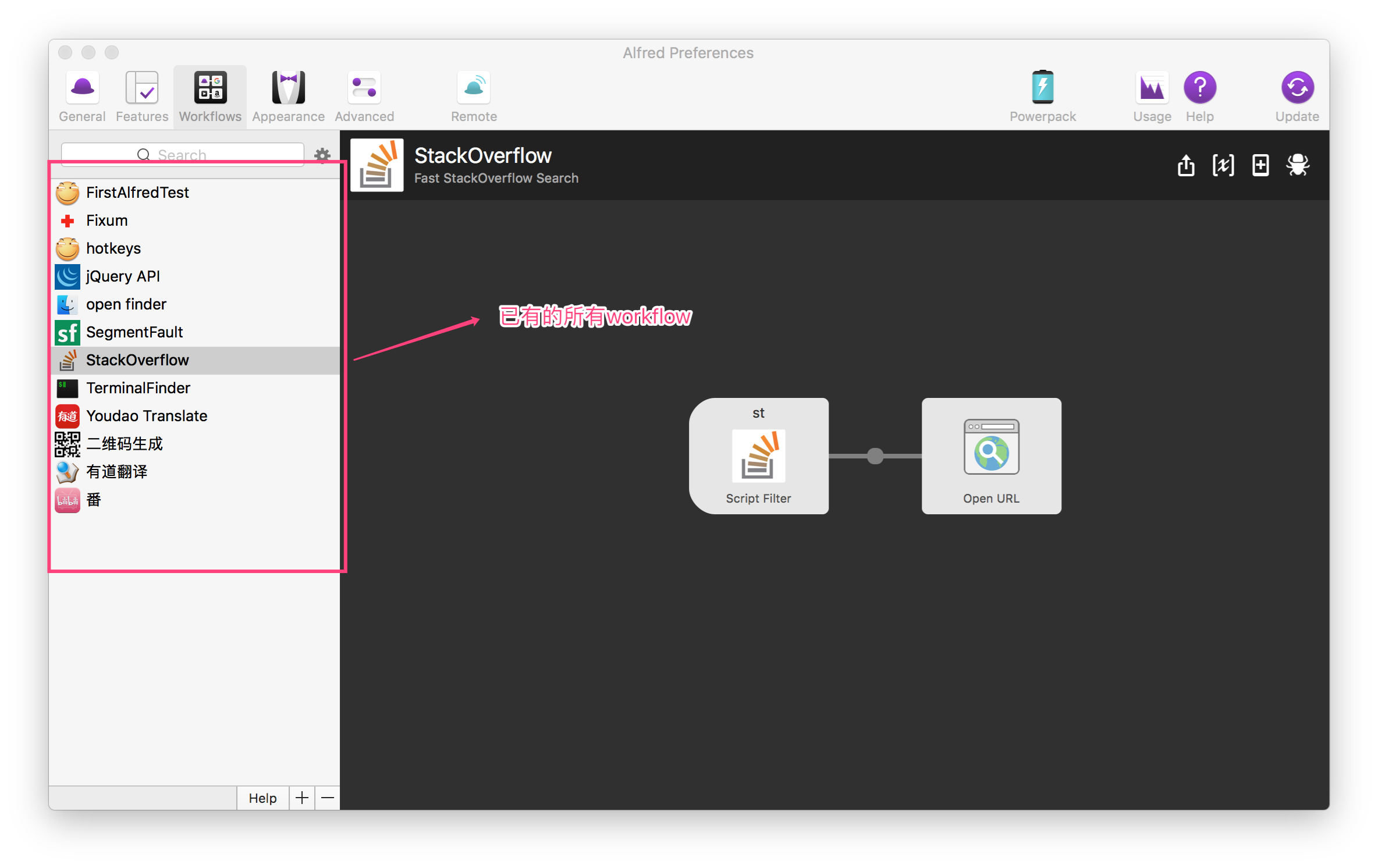
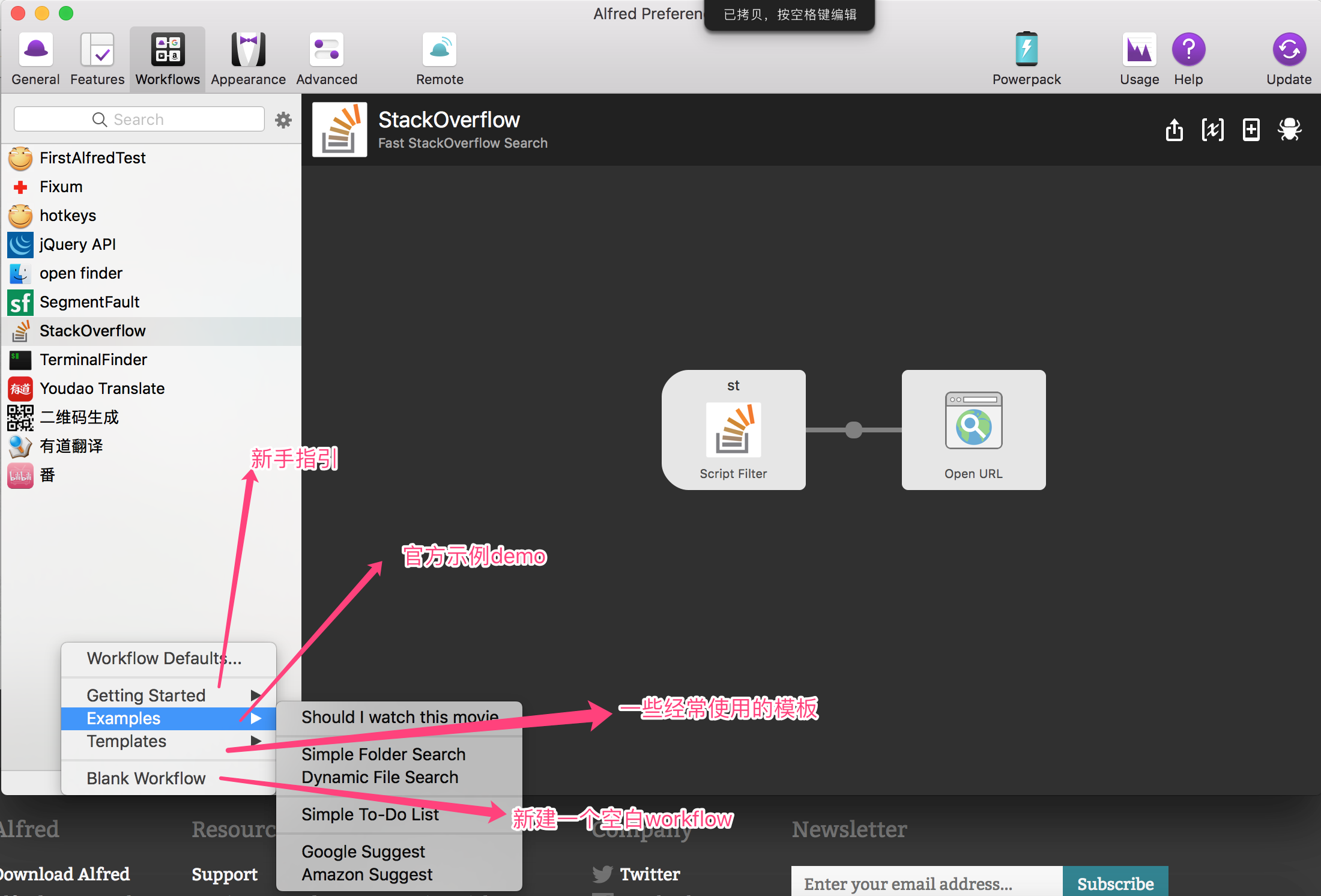
点击左下角 + 号,可以新建workflow或者查看一些官方的模板以及上面提到的官方的demo示例。
好了,基本操作界面就介绍那么多,下面就开始我们的workflow之旅吧!
准备工作
由于workflow功能是付费的,所以需要提前购买。具体类型、金额可以参考官网购买地址:官网购买地址。开发语言我们选择的是python2.7,一个是语言简单,另外个是python有很多现成的workflow的库,这些库帮助我们屏蔽了和alfred的交互,让我们专注业务数据的开发,例如:,https://github.com/deanishe/alfred-workflow/。范例里我们即使用这个库来进行开发。
开发流程
基础概念
在开发之前我们需要理解workflow的几个基本概念
- Triggers
- Inputs
- Actions
- Outputs
Triggers
Triggers是触发器,不是必须内容,一般绑定某个快捷键来触发指定的workflow。
Inputs
inputs是我们使用workflow的核心,inputs主要是控制你在alfred窗口输入快捷键和关键字以后展示的内容,以最常用的有道翻译为例:
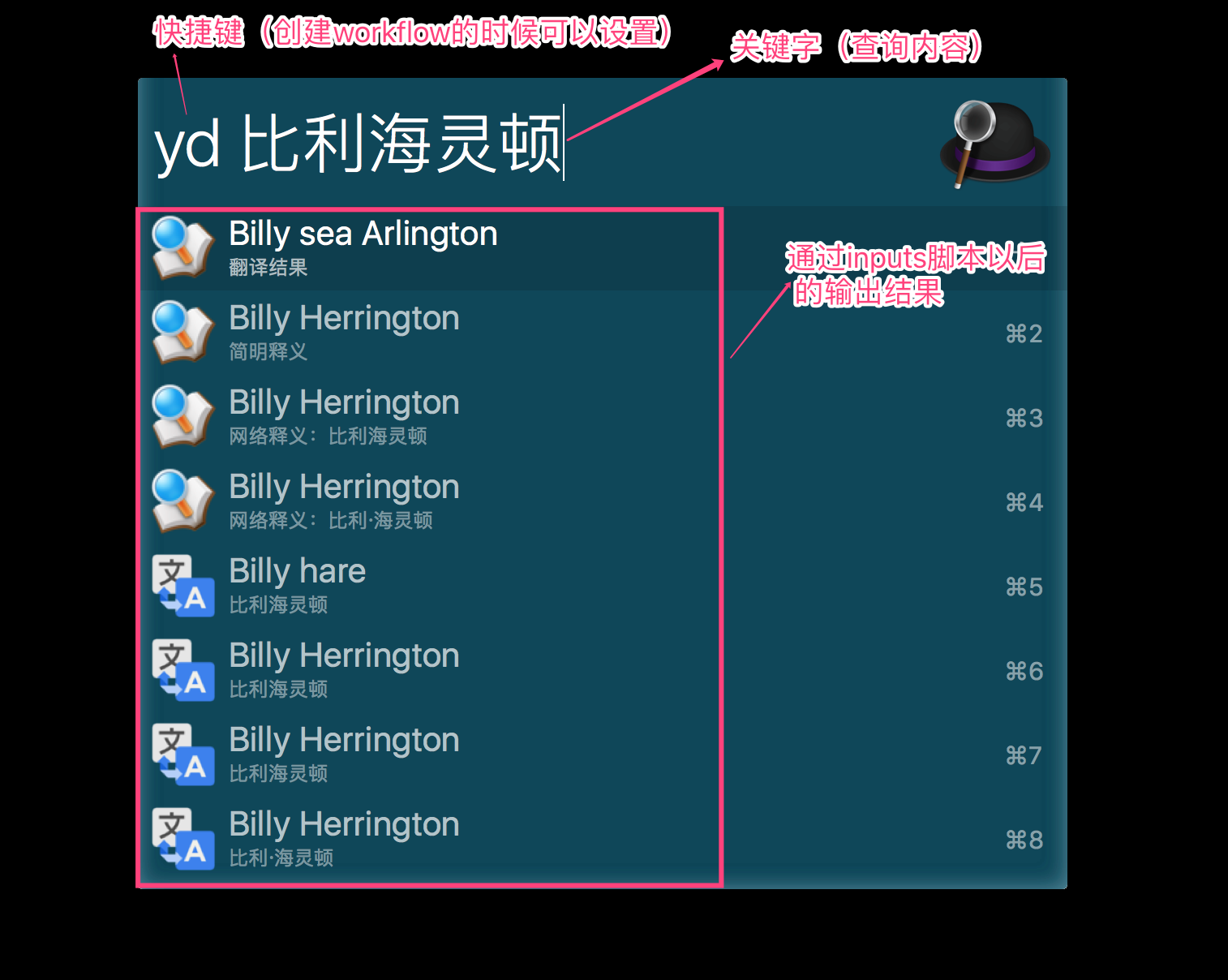
可以看出inputs就是我们需要重点开发的东西,因为Inputs可以使关键字通过脚本转化为许多列的结果展示给我们,而这个正是我们需要的。实际上workflow展示出的结果在脚本中的表现形式就是一个xml文件,示例如下:
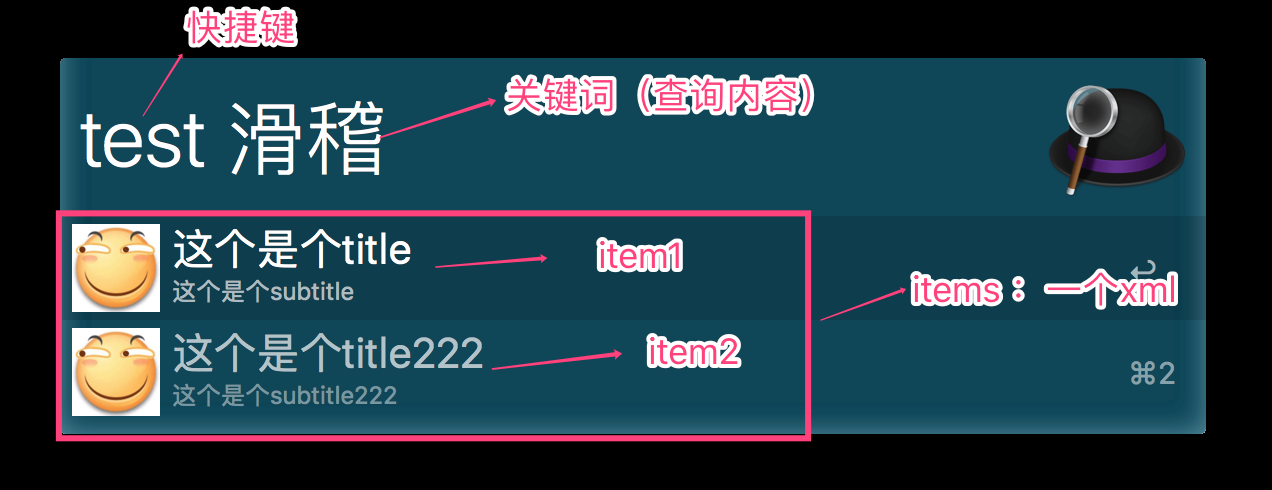
对应的xml:
<?xml version="1.0"?>
<items>
<item uid="1" arg="参数1" valid="yes">
<title>这个是个title</title>
<subtitle>这个是个subtitle</subtitle>
<icon>icon.png</icon>
</item>
<item uid="2" arg="参数2" valid="yes">
<title>这个是个title222</title>
<subtitle>这个是个subtitle222</subtitle>
<icon>icon.png</icon>
</item>
</items>
可以看到每行展示的内容被定义为一个item,每个item有一个uid,arg 。uid是每个item的唯一编号,不常用。arg指的是当在这个item上触发事件的时候(例如点击enter),传递给下一个脚本或者说Actions脚本的入参。实际上我们编写workflow的核心就是为了生成这个xml**。**
Actions
actions对应选中项(item)选中点击以后的操作,例如根据选项打开一个网页等。
Outputs
Outputs一般用于显示操作的结果,提示操作成功与否,以Post Notification(提示操作状态)、Copy to Clipboard(copy到剪切板)较为常见。
还是以有道翻译为例,以上四个概念如图:
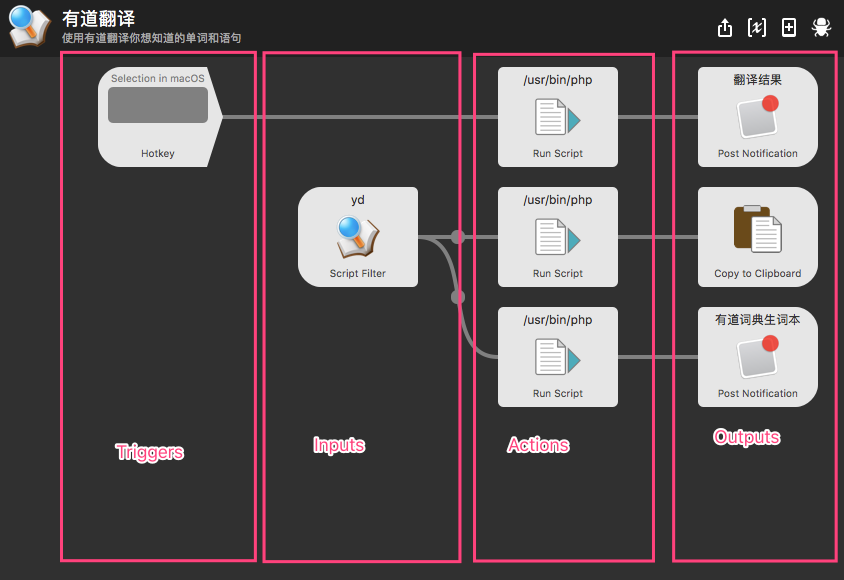
看图可以总结出workflow的基本工作方式:

需要注意的是,从图上可以看到整个工作流程中,最初的输入是用户输入的关键字,但是随着流转上一个脚本的输出是下一个脚本的输入。
好了到此我们workflow的基本概念就介绍完毕,现在让我们直接进入workflow的开发工作吧。
脚本开发
个人总结出来的一个workflow的开发流程如下:
- 明确需求
- 画思路图(熟练以后,直接和步骤3合并)
- 写脚本,调试
下面我们就根据以上三个步骤来示范一个workflow的开发。
明确需求
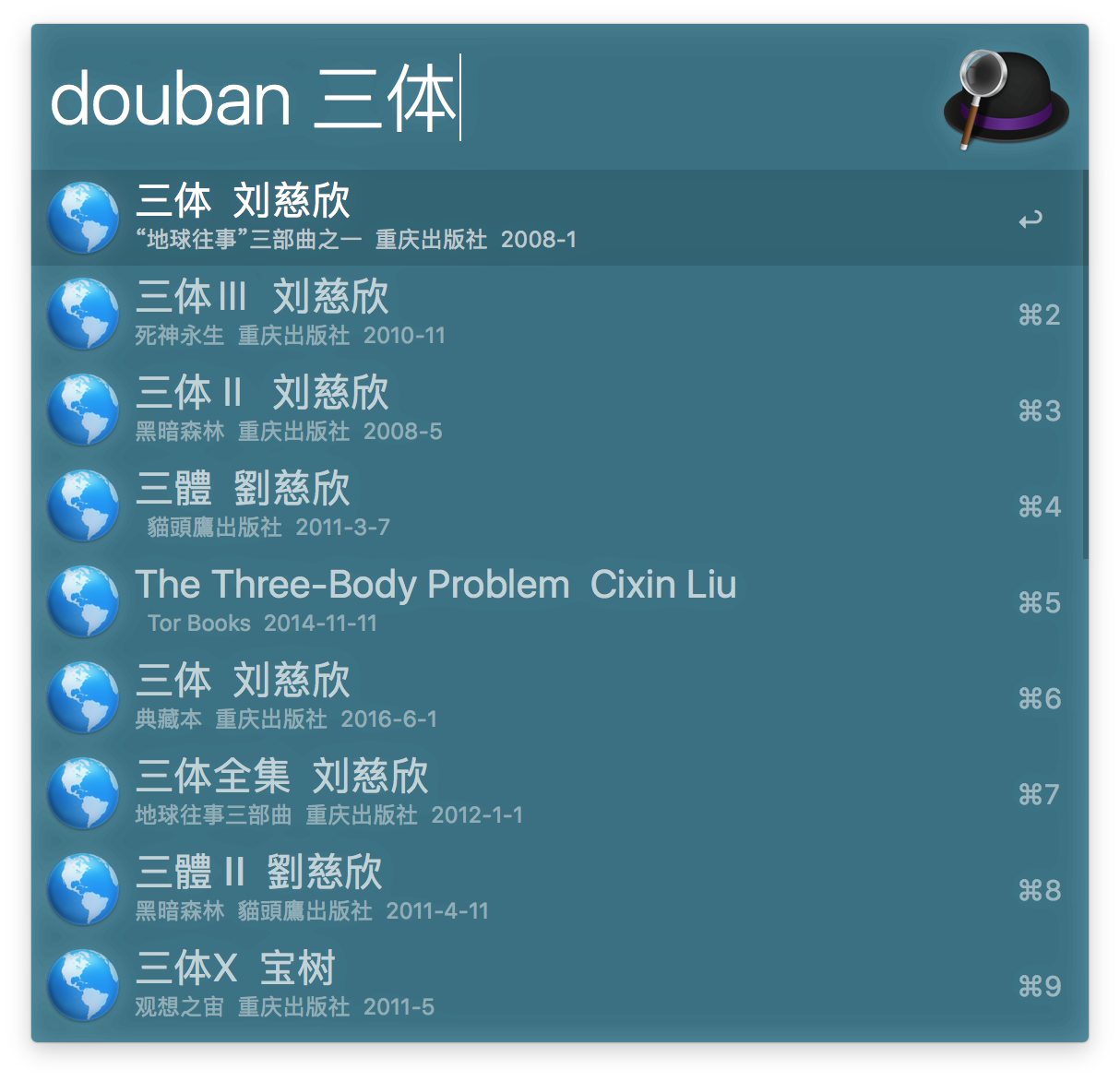
例如我想开发一个豆瓣搜索图书的workflow,当我输入书名字的时候,可以在展示出所有关联的书的列表,然后每条记录展示书的名称,书的作者以及出版年份。我们在脑子里脑补了一下,大概做出来的效果如下:

画思路图
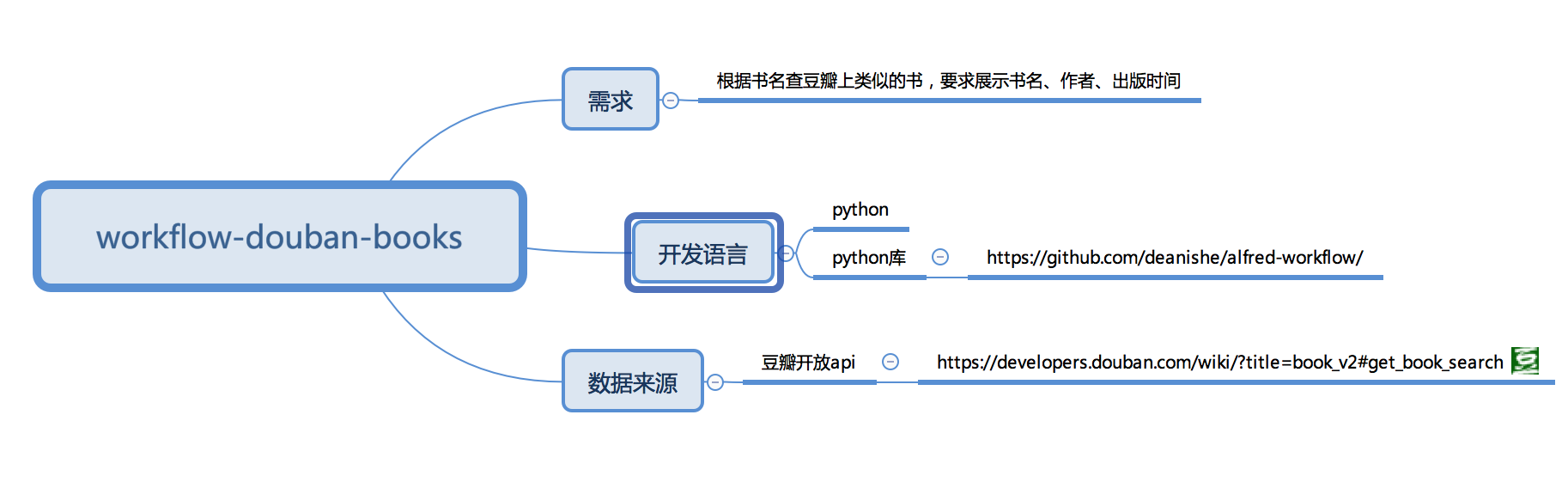
写脚本
因为我们使用的python的第三方库,而这个第三方库其实作者已经写了非常详细的使用方法以及附了2个范例,可以看原文:http://www.deanishe.net/alfred-workflow/tutorial.html(强烈建议有余力的同学读原版教程),这里我就简单的结合我们的需求加工(翻译)下:
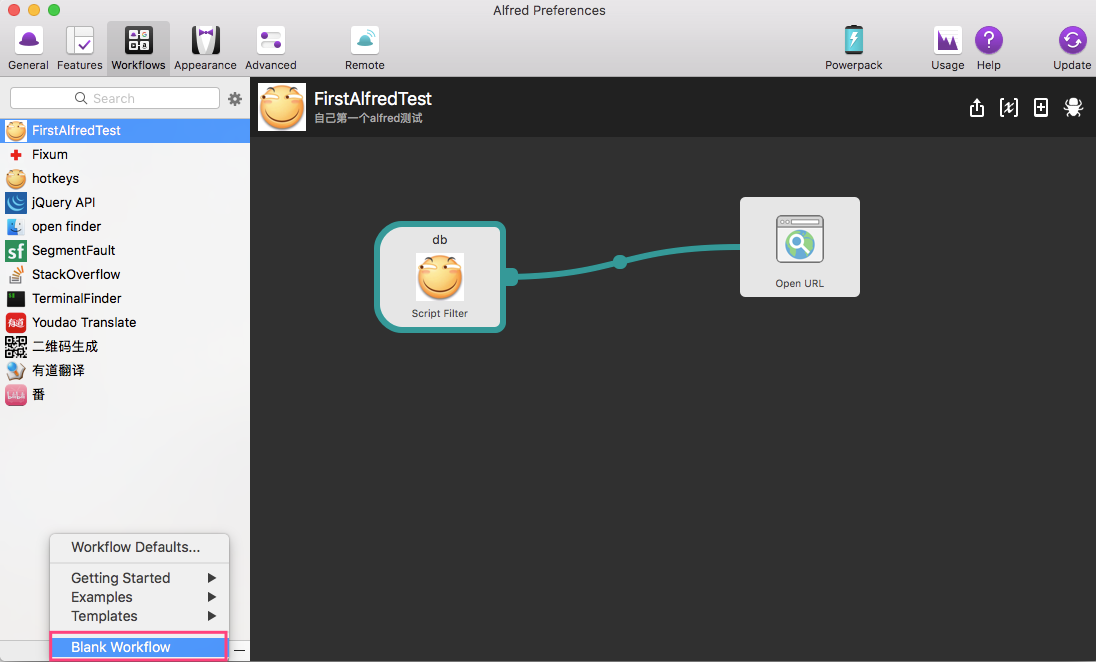
1、创建一个workflow
首先,创建一个新的,空白的workflow,如图:
2、简单描述下你的workflow
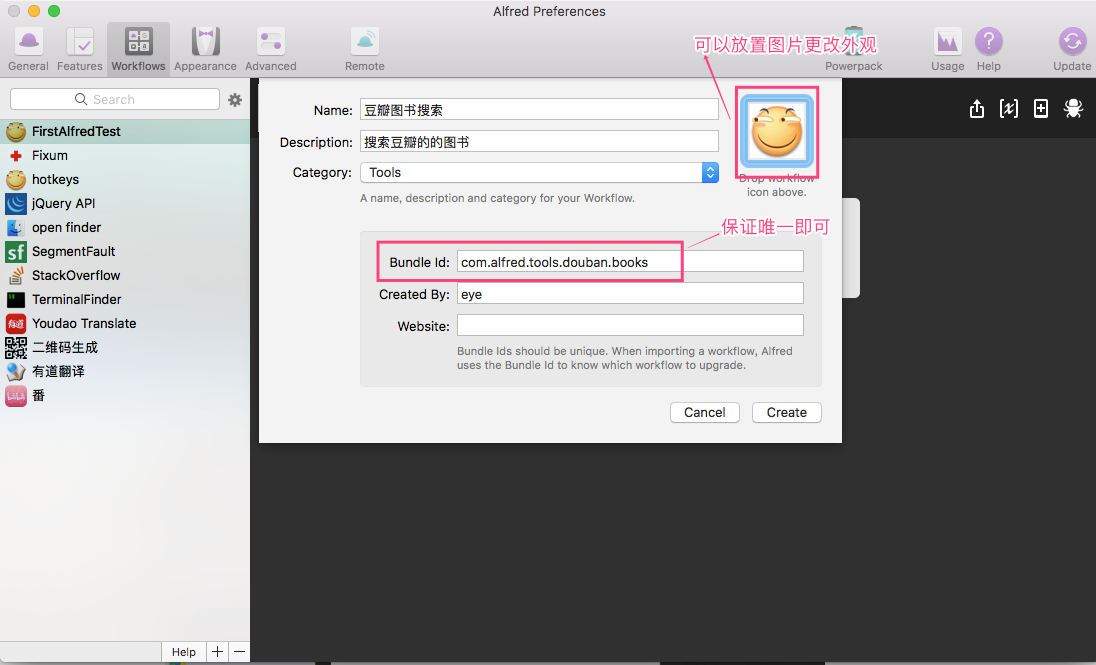
点击Blank Workflow以后会跳出workflow的基本配置窗口,图如下,需要注意的是bundle Id的填写,该字段需要在你所有的workflow理保持唯一(类的全路径名)。可以将一个图片拖动到workflow上来改变workflow的外观,填写完毕点击create即可保存。
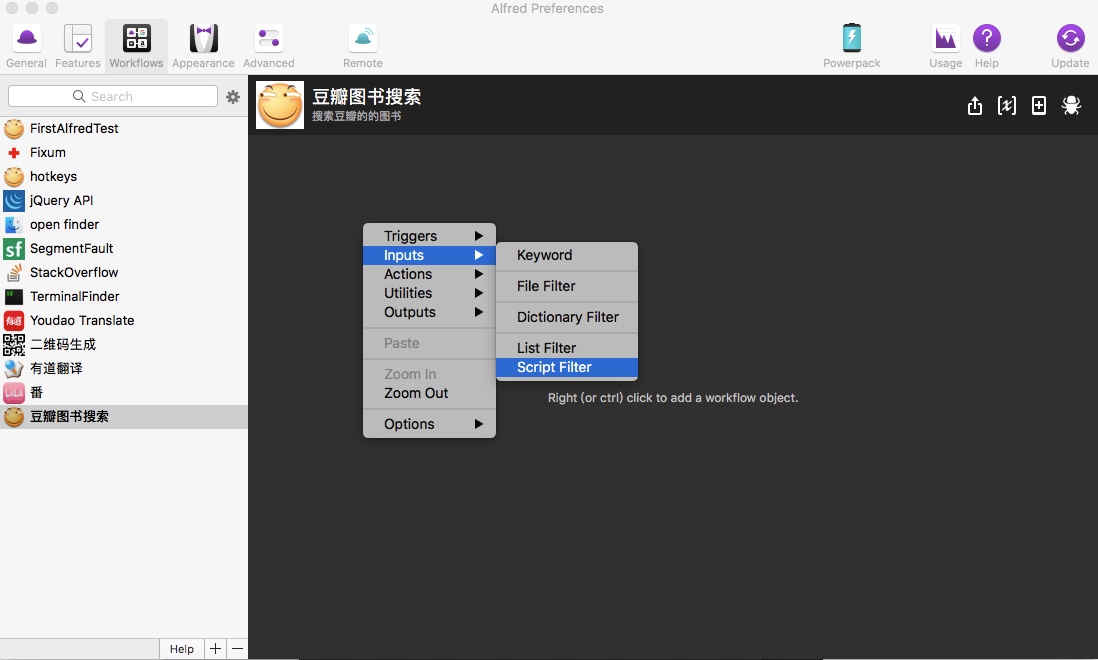
3、添加Script Filter
双击新创建的workflow,在空白处右键创建一个Script Filter,通过上面的基础概念说明我们可以了解,Script Filter是Inputs的一种,而Inputs的作用是接收用户输入(可选),然后根据用户输入通过脚本过滤展示数据。
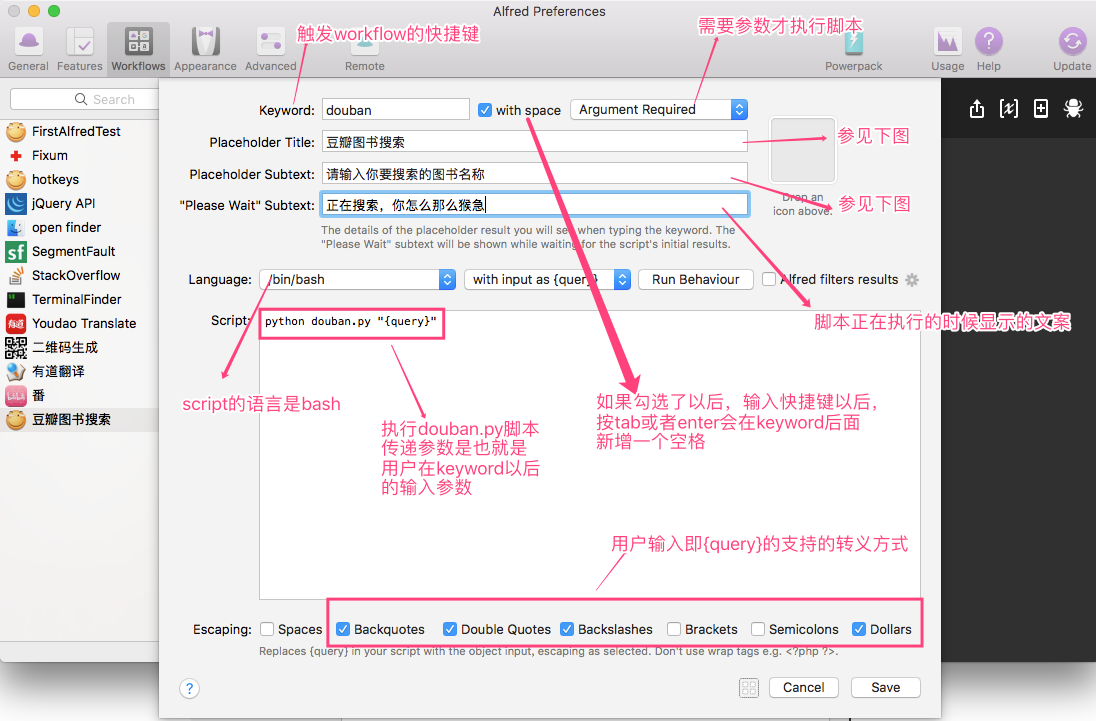
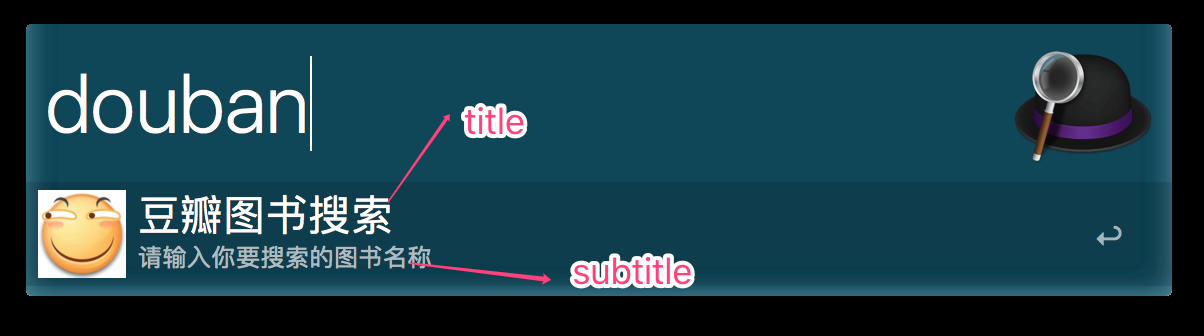
在创建Script Filter的时候,我们需要填写一些基本信息,如图。keyword表示该workflow的触发的快捷键,参考基础概念图中的yd 和 test。因为我们搜索豆瓣图书的时候是需要输入书名字的,所以选择 Argument Required,这个其实就是强制要求必须输入参数才会执行脚本,当然有的workflow也是不需要入参的。
4、编写调试你的python脚本
创建完Script Filter以后在workflow上右键,open in finder,打开workflow的本地文件夹:
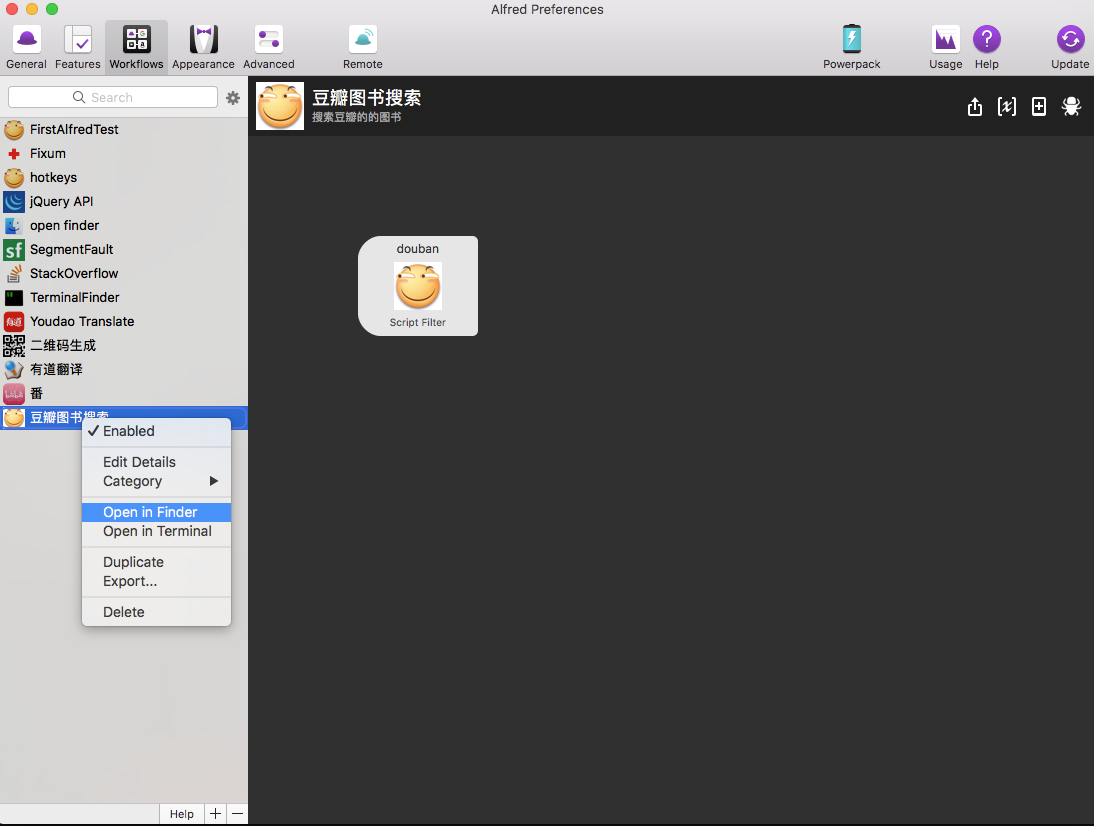
打开以后一个空白的workflow应该是如下的:
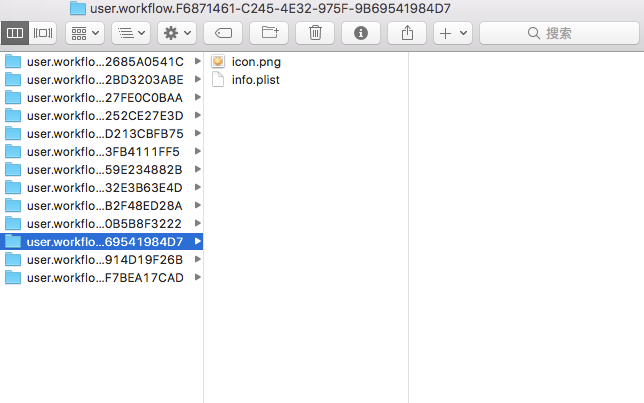
可以看到只有一个图标和一个info.plist,可以打开info.plist查看,里面是该workflow的所有配置信息,这里就不说了。
为了正常使用该python的第三方库,我们需要在github上下载该库:https://github.com/deanishe/alfred-workflow/,并且复制其中的workflow文件夹到你本地的workflow文件夹,复制好以后你本地的workflow文件夹列表应该如下:
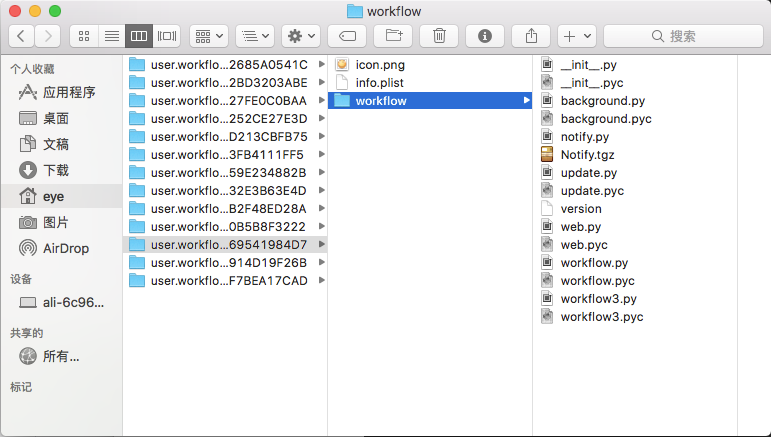
同时我们需要在该文件夹下创建我们的主要脚本文件,douban.py(在script filter中配置的),最终全部创建好以后如下:
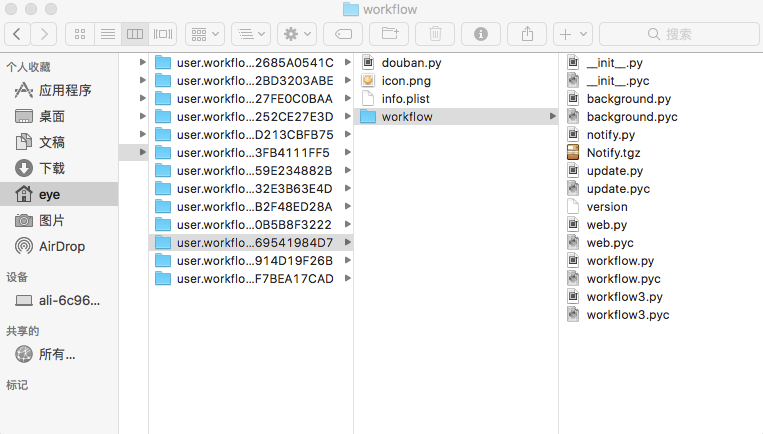
最后我们只需要编写douban.py的代码即可。ps:比较方便一点的是先在编辑器中创建文件,然后编辑调试好代码直接复制过去即可。
限于篇幅就不一一说明每行代码方式了,如下:
# -*- coding: utf-8 -*-
import sys
import requests
from workflow import Workflow, ICON_WEB
def get_recent_posts(query):
# 豆瓣开放api
url = 'https://api.douban.com/v2/book/search'
# 查询参数
query_string = dict(q=query)
headers = {
'cache-control': "no-cache",
}
r = requests.request("GET", url, headers=headers, params=query_string)
# 如果有异常 抛出
r.raise_for_status()
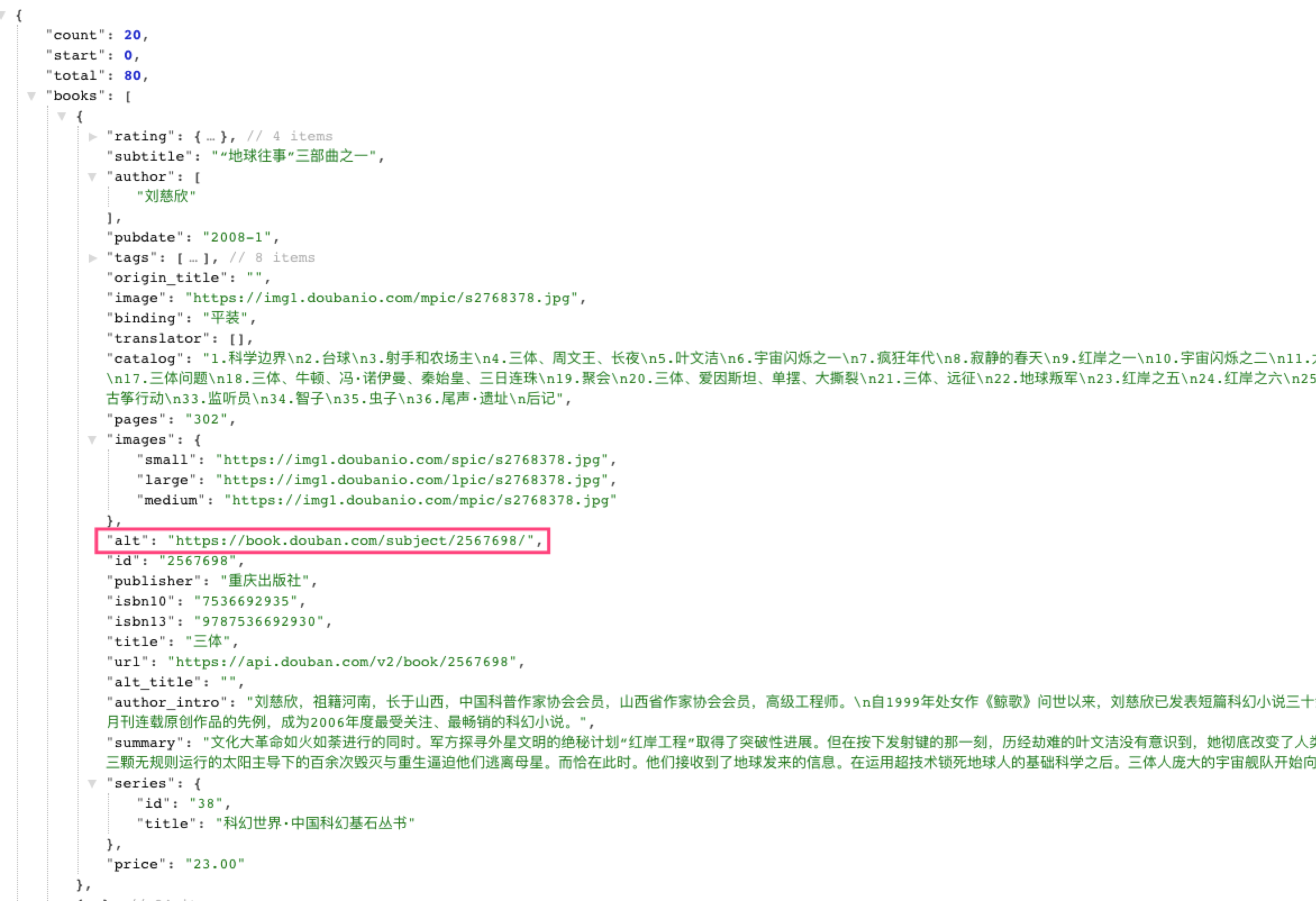
# 获取json数据 范例参见 https://api.douban.com/v2/book/search?q=三体
result = r.json()
# 获取搜索的书籍数据
posts = result['books']
return posts
def main(wf):
# 从alfred获取query
if len(wf.args):
query = wf.args[0]
else:
query = None
# 根据query获取数据
posts = get_recent_posts(query)
# 封装xml,即展示的页面需要什么数据,拼装数据
for post in posts:
title = post['title'] + " " + post['author'][0]
subtitle = post['subtitle'] + " " + post['publisher'] + " " + post['pubdate']
wf.add_item(title=title, subtitle=subtitle, arg=post['alt'], valid=True, icon=ICON_WEB)
# 把数据发送给alfred展示
wf.send_feedback()
if __name__ == u"__main__":
# 新建workflow对象
wf = Workflow()
# 执行main方法
sys.exit(wf.run(main))
可以看到,使用第三方库开发workflow的流程如下:
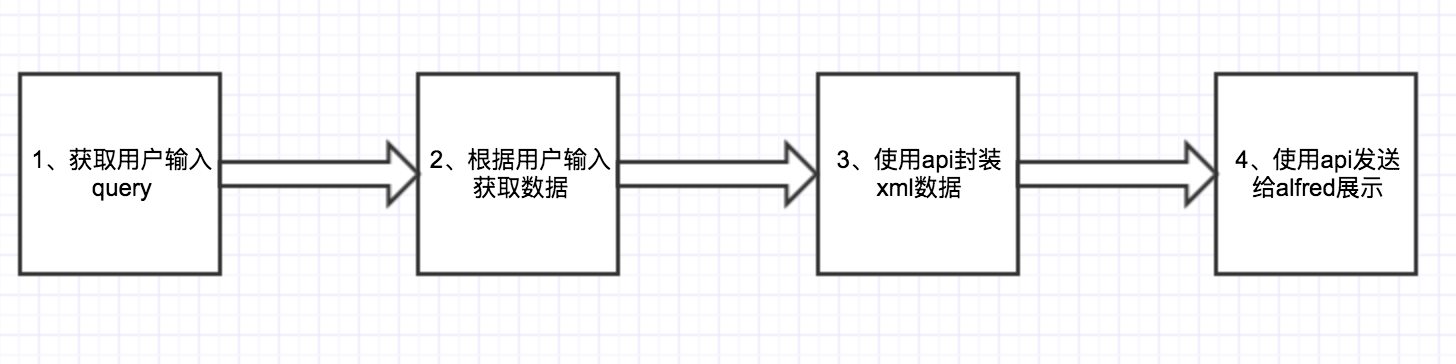
其中只有2,和3的封装过程需要我们编写代码,第三方库完全屏蔽了我们和alfred的交互,可以让我们更专注在数据的开发上。
以上代码编写完,测试效果如下:
5、添加workflow的actions
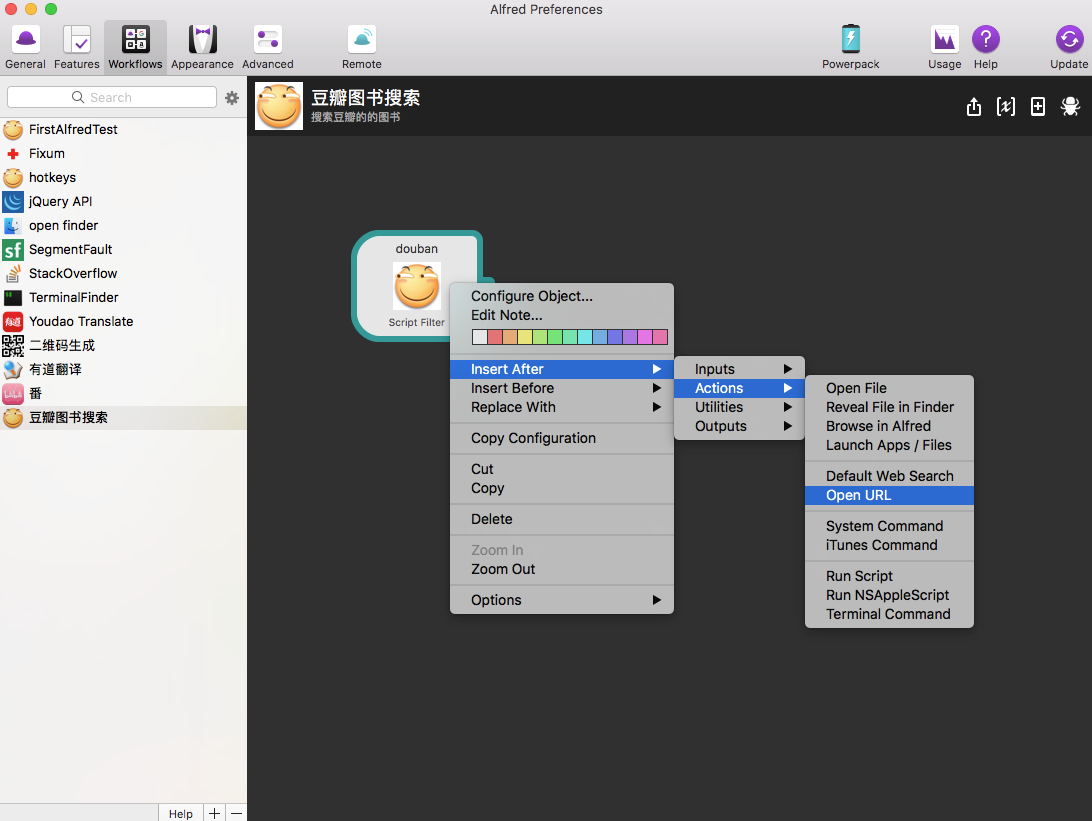
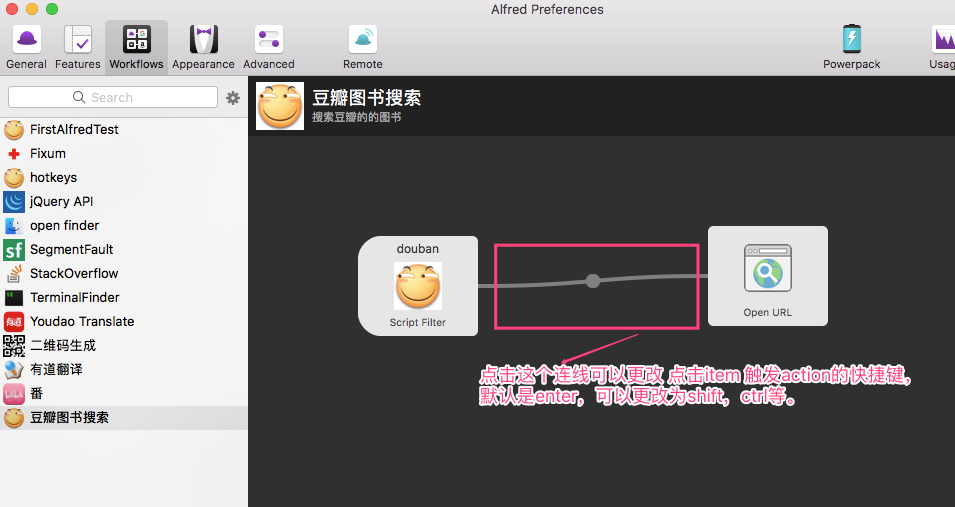
我们搜索了书籍,如果看到感兴趣的书,肯定想着说打开一些书的主页看下,那么难道还需要跑到豆瓣上再去打开?当然是不需要的。所以我们需要一个【选中一个选项直接enter或者shift打开这本书对应的豆瓣主页】的功能,那么actions就是做这个动作的。在script filter上右键 添加一个actions:
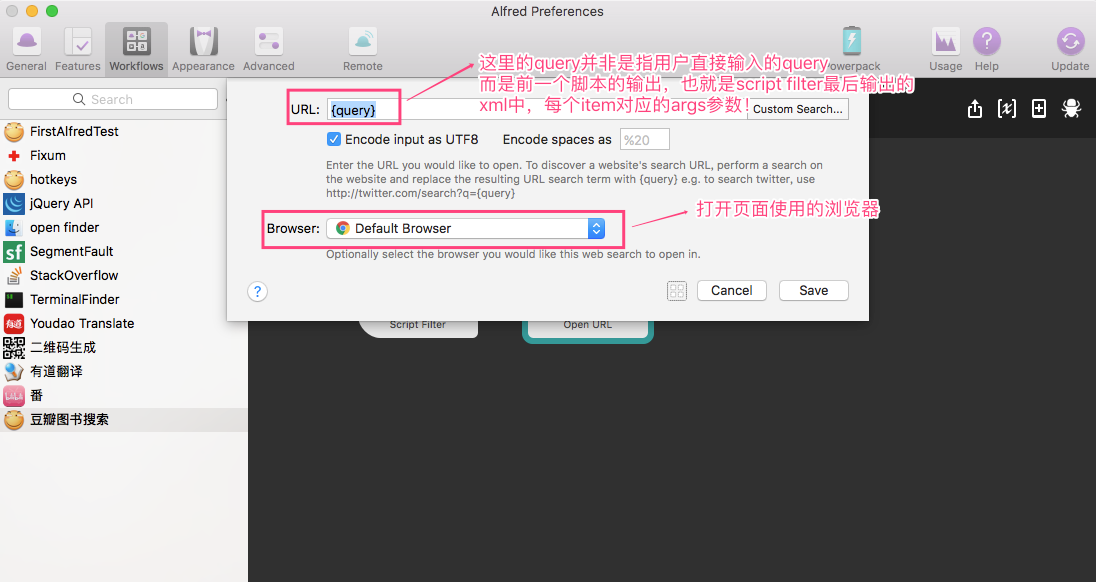
需要注意的是这里的query并非是用户一开始输入的query,因为触发这个动作是点击script filter中的一个item触发的,所以这里的query指的是【基础概念】章节介绍的xml格式里面的每个item对应的arg,参照我们python的代码里表示的是每本书的主页的链接地址!
wf.add_item(title=title, subtitle=subtitle, arg=post['alt'], valid=True, icon=ICON_WEB)
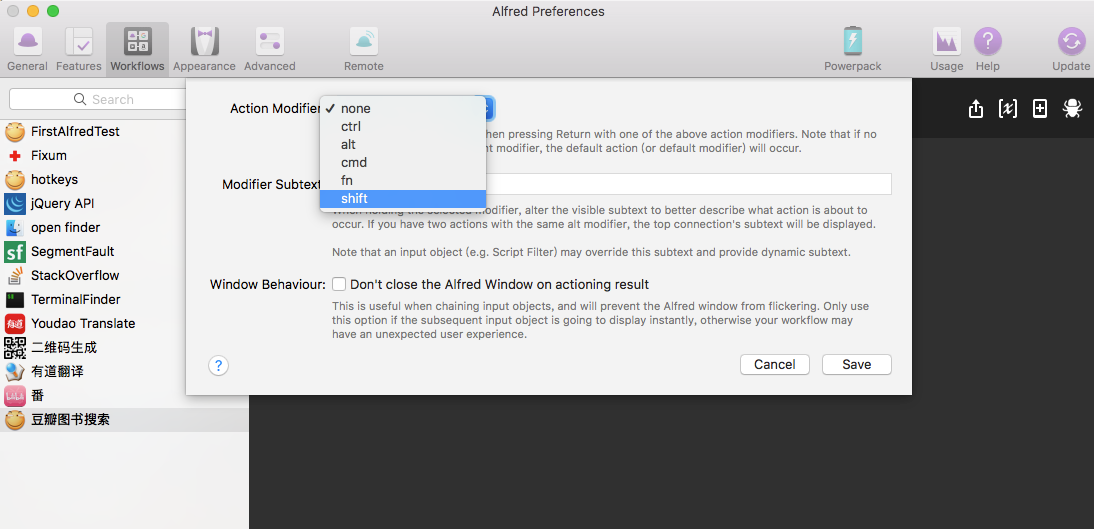
当然,如果你想更改点击的快捷键,可以单击script filter 和actions的链接:
好了到此为止,我们就大功告成了,这时候点击alfred搜索出来的数据,可以直接使用chrome打开书的主页了,当然既然用到了第三方库,第三方库还是有很多高级功能的,比如缓存,主要目的是放置被api服务器ban掉,可以把搜索的数据缓存在本地,具体的api可以参考该第三方库的文档:http://www.deanishe.net/alfred-workflow/api/index.html。
- 如果需要写workflow的话也没必要亲自写。有很多网站维护了很多的常用的workflow,比如:http://alfredworkflow.com/ 里就有各种常用的。